

4min read
Are AI Reasoning models really “thinking”?
Why This Matters?
Large language models (LLMs) now use chain-of-thought (CoT) prompts. They generate step-by-step traces before answering. Early results showed CoT could boost performance on math, logic, and planning. But most tests mix training data and test problems. We can’t tell if models truly reason or simply memorize patterns.
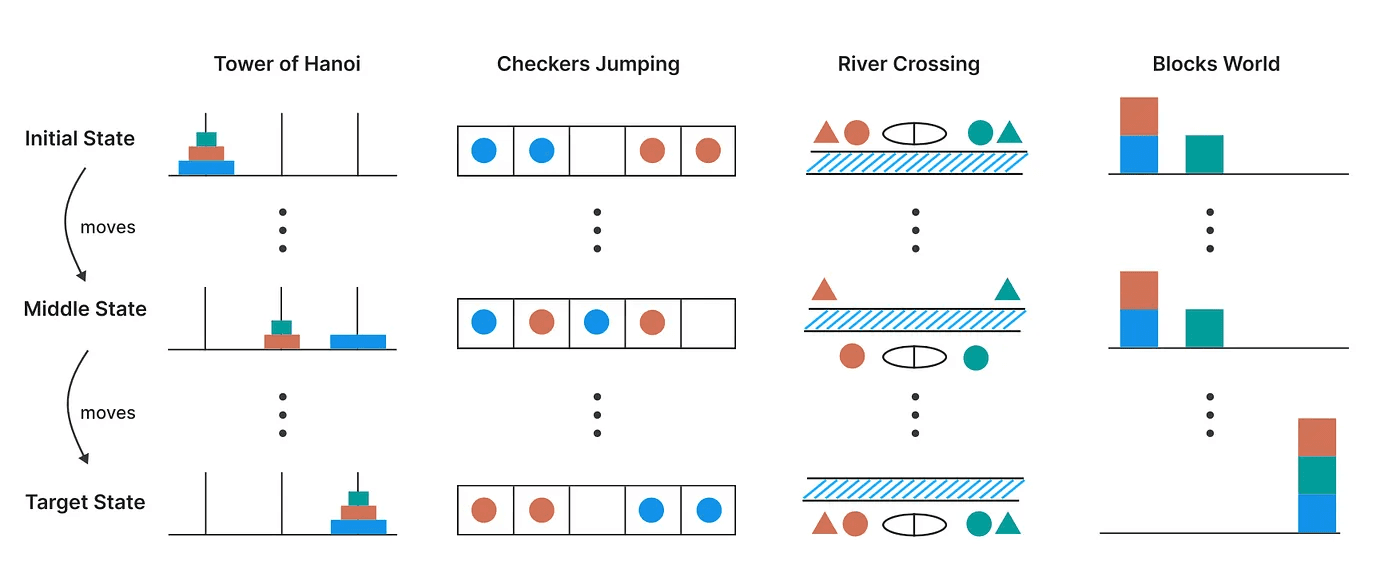
Apple’s research team built a fresh approach. They designed four classic puzzles with adjustable difficulty and perfect simulators. This lets them measure real reasoning ability without any data contamination.
Link to Paper: https://machinelearning.apple.com/research/illusion-of-thinking
The Four Puzzles
Tower of Hanoi
The game is to Move discs between three pegs. Rule: Never place a larger disk on a smaller one.Checker Jumping
Players need to Swap two groups of tokens on a checkerboard by jumping. Rule: tokens jump over adjacent tokens into empty spots.River Crossing
Ferry characters across a river without breaking safety rules (e.g., wolf can’t be left with goat).Blocks World
Game is to Restack blocks on a table to match a goal arrangement.
Model Comparison
Researchers tested two styles of LLMs on these puzzles:
Direct Models: They see the puzzle and the question, then output a final answer.
Chain-of-Thought Models: They first generate a reasoning trace many “thought” tokens then give the answer.
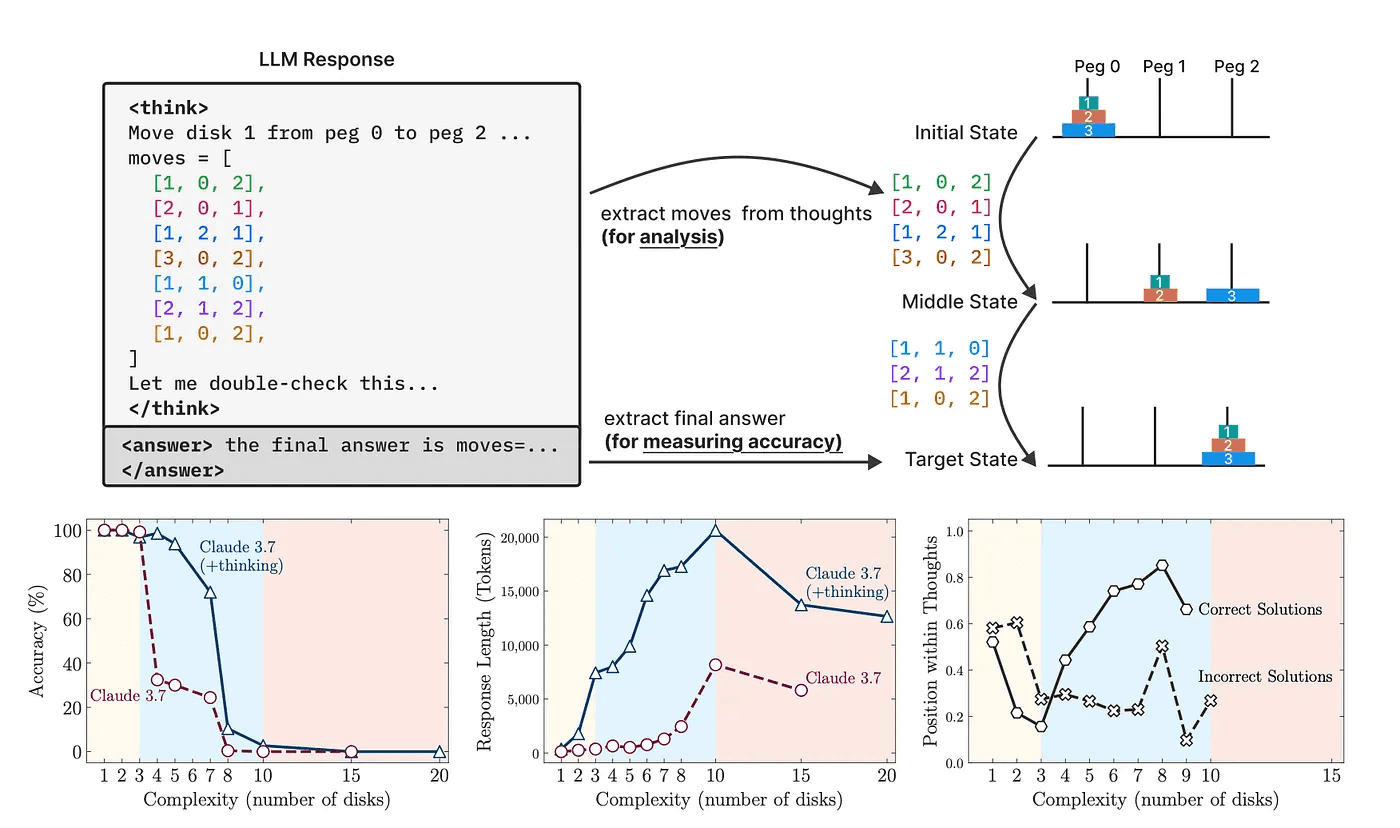
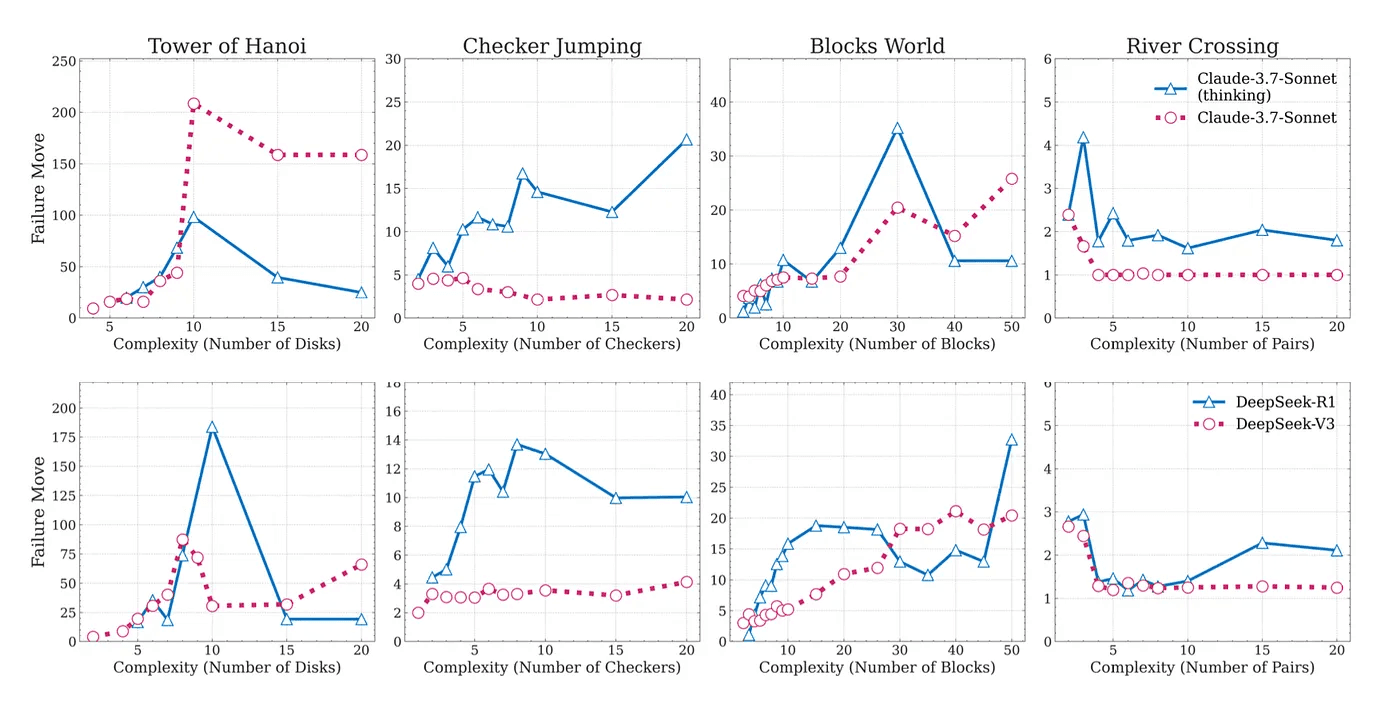
Both types ran on hundreds or thousands of puzzle instances, at varying levels of difficulty. The team measured accuracy, token usage, and the content of CoT traces.
Three Phases of Performance
As puzzle complexity grows, models show three distinct behaviors:
Easy Tasks
Direct models win. CoT models waste time “thinking” step by step and perform worse.Medium Difficulty
CoT models pull ahead. Extra reasoning tokens help solve puzzles that stump direct models.High Complexity
Both types collapse to 0% accuracy. Even with huge token budgets, no model solves the hardest versions.
This reveals a surprising ceiling: more “thinking” doesn’t push models past a certain threshold.
Peeking Inside the Thought Trace
The team didn’t stop at accuracy. They analyzed CoT traces to see what “thinking” really looks like:
Overthinking: Models often hit the correct intermediate move early. Then they continue exploring wrong paths. That wastes compute and leads to failure.
Token Budget: As puzzles grow harder, models initially ramp up token usage. But near the failure point, they use fewer tokens, they literally give up before exploring all options.
These patterns hold across different LLM architectures and sizes.
Even with a Recipe, They Fail
To test if hints help, researchers provided the exact algorithm for each puzzle in the prompt. You’d think this would boost performance. It didn’t. Models still hit the same difficulty ceiling. The hard limit remains, even when they know the rules in detail.
Final Thoughts
Chain-of-Thought Isn’t Real Reasoning
CoT helps a bit on medium tasks, but it’s not genuine logic. It’s pattern matching over extended tokens.Fundamental Limits Exist
LLMs fail completely on sufficiently hard, rule-based puzzles — even with more computing power or explicit algorithms.Overthinking Can Hurt
Extra reasoning can waste tokens and reduce accuracy on easier tasks.
Stay tuned to rKive for more deep dives into cutting-edge AI and security research. We’ll track new innovations, break them down simply, and highlight real breakthroughs, so you never miss a beat!
Link to my medium profile: https://medium.com/@ruchirkulkarni/